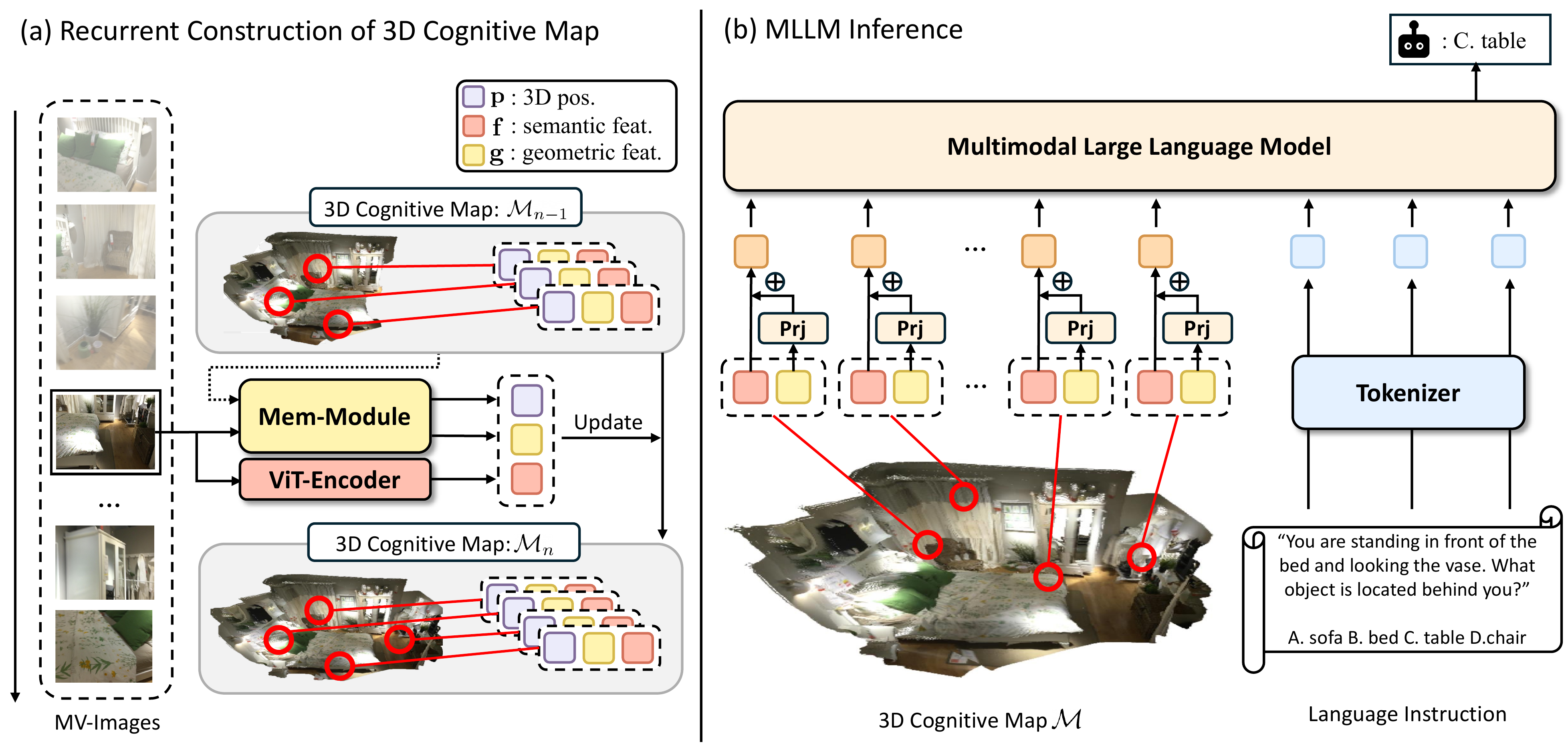
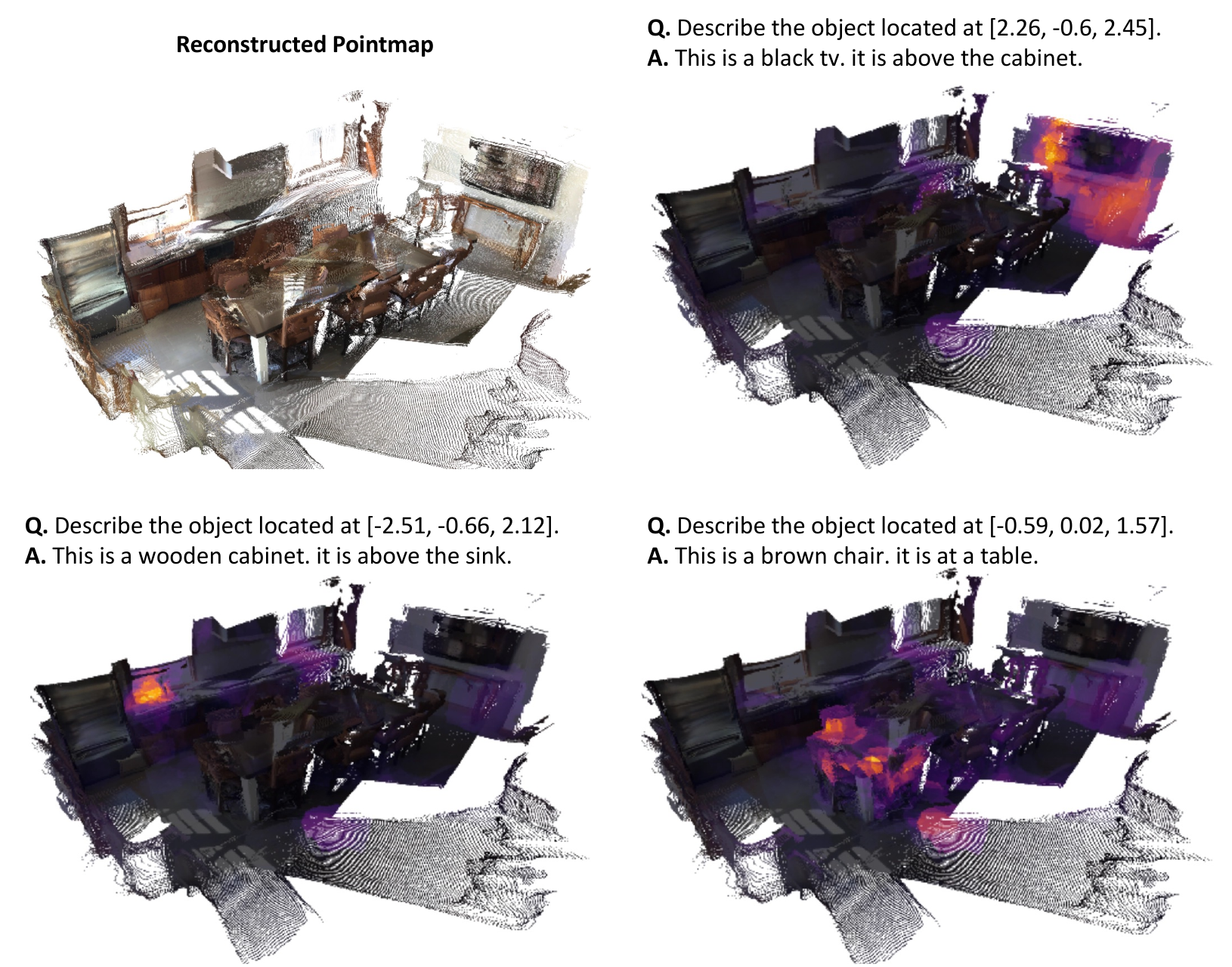
Precise spatial understanding from multi-view images remains a fundamental challenge for Multimodal Large Language Models (MLLMs), as their visual representations are predominantly semantic and lack explicit geometric grounding. While existing approaches augment visual tokens with geometric cues from visual geometry models, their MLLM is still required to implicitly infer the underlying 3D structure of the scene from these augmented tokens, limiting its spatial reasoning capability. To address this issue, we introduce Cog3DMap, a framework that recurrently constructs an explicit 3D memory from multi-view images, where each token is grounded in 3D space and possesses both semantic and geometric information. By feeding these tokens into the MLLM, our framework enables direct reasoning over a spatially structured 3D map, achieving state-of-the-art performance on various spatial reasoning benchmarks.